Introductions
Collaborators: David Wolff and Nicolas Finkelstein
Emails:
- davidwolff2020@u.northwestern.edu
- nicolasfinkelstein2020@u.northwestern.edu
Course: EECS 349 Machine Learning Northwestern University
Task
The task of this project is to provide a prediction to players who are considering on surrendering early in a League of Legends game. League of Legends is a highly competitive, 5v5 online video game played by over 67 million people worldwide. Therefore, deciding on whether or not to surrender early (commonly known as forfeitting or FF’ing) not only saves time for the players, but also alleviates stress that may occur during the game since games can range anywhere from 30-50+ minutes.
Approach
The data we used for this project was acquired here. The original dataset was divided up into 7 separate csv files consisting of both team-centered and individual player-centered data. Therefore, we cleaned the data and made edits to be able to merge the sets into one. Part of the process even involved creating a bag-of-words like attributes based on what champions were selected! To see the full data cleaning process, click here. Since we started off with approximately 240 attributes, we had to use our intuition based off our previous experiences with the game to narrow our list of attributes down to 144 (138 being champions). This facilitated and sped up our training and testing. Once we had our data ready for model selection, we ran different learners and ultimately decided to use Decision Trees (CART) as our primary learner.
Choosing a Best Model
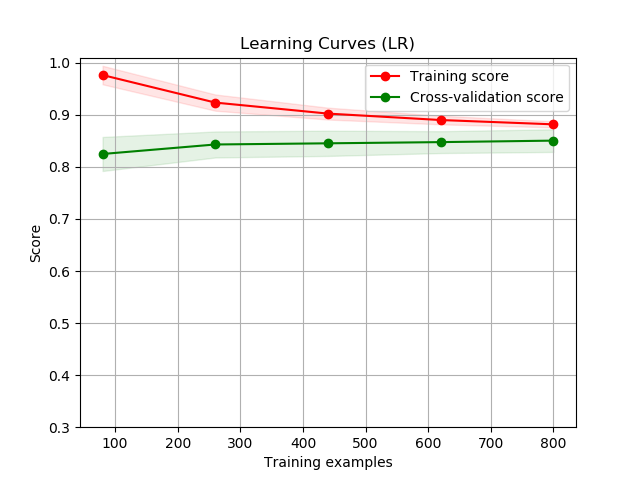
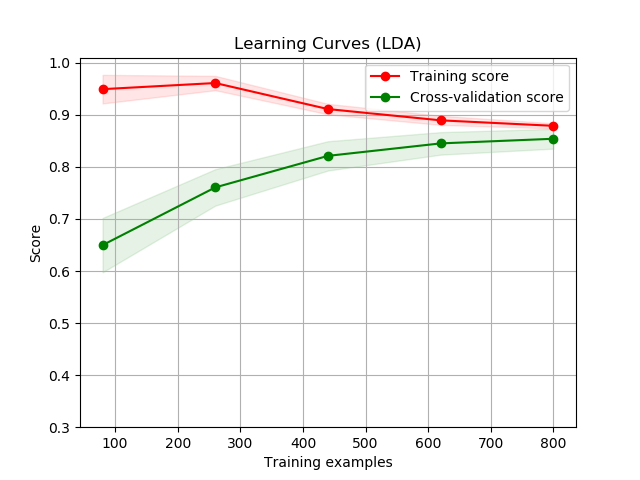
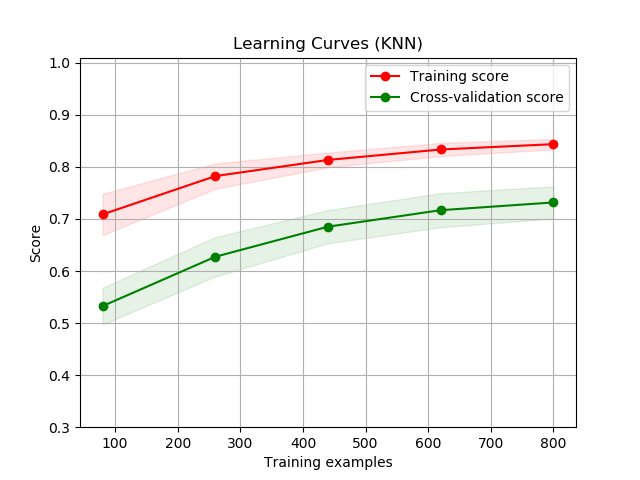
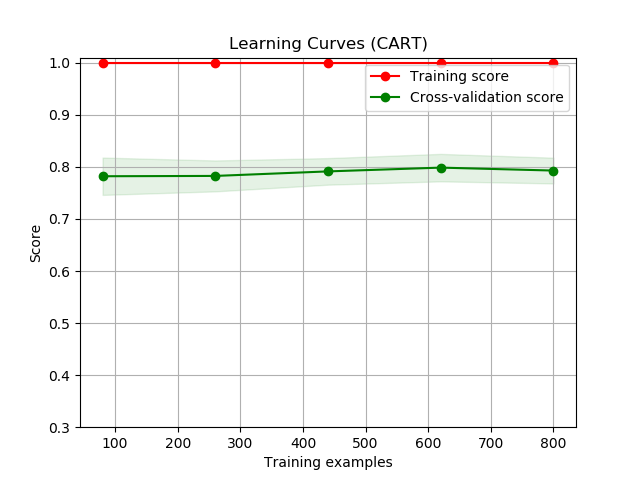
First, there were 6 learners that we were deciding on using. These learners are: Logistic Regression, Linear Discriminant Analysis, K Neighbors Classifier, Decision Tree Classifier, Gaussian Naive Bayes, and Support Vector Machines. To decide which learner to use, only about 1000 samples were chosen from the entire data set to learn each type of learner. For each learner, we created learning curve graphs for both the validation set (which was set to be 20% of the 1000 samples) and the training set. This can be seen below in the Illustrations and Graphs section of this paper.
At first glance of all of these figures, the Logstic Regression (LR) and the Linear Disciminant Analysis (LDA) curves look way higher than any of the other figures. But we chose to use Decision Trees (CART) instead because the difference between it and the highest scoring models was insignificant and we wanted to know which characteristics from the early game will most likely determine the end result: victory or defeat. Furthermore, during our model creating of LDA, we recieved multiple warnings about colinear and inconsistent variables that deterred us from picking these learners. Considering that the accuracy for Decision Trees were also pretty accurate and nice (scoring 79.751%), we chose to use CART/DT.
Illustrations and Graphs
In the figures, the shaded area around the plots are the first standard deviations and score is based on accuracy, where highest accuracy is 1 (100%).
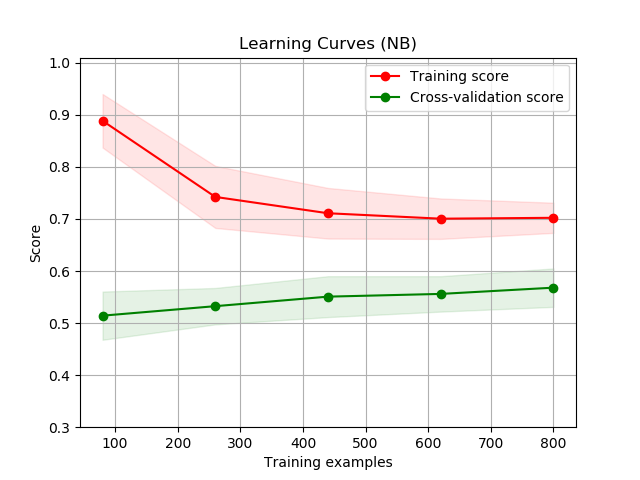
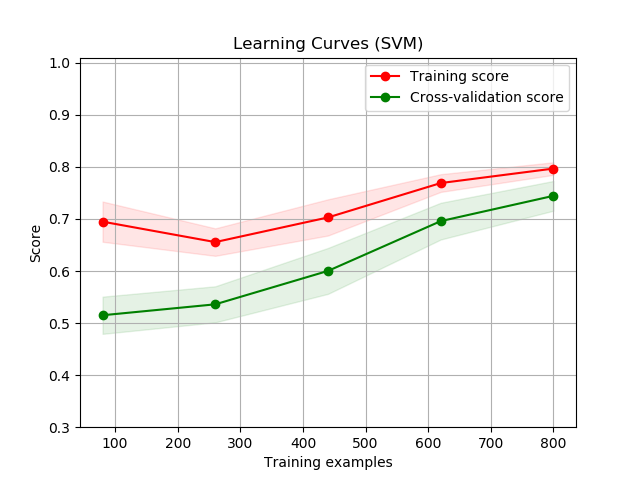
The Process: Picking our Attributes
With our raw data, we were given the following individual data and team data:
Individual:
- champion played
- Wards placed
- Summoner spell of each player
- Role of each player
- first blood
- items each player ended with
- trinket used by each player
- number of kills by each player
- number of deaths by each player
- number of assists by each player
- largest sprees
- physical/magic dmg dealt
- healing done
- damage to champs
- damage taken
- damage to turrets
- etc…
Team:
- Side (Blue vs Red)
- First baron
- First turret
- First inhib
- First dragon
- Bans
- Rift herald
- Season
- Patch Version
- Server/Platform
Originally, we thought there were roughly 80 attributes to consider over 360,000+ data points. However, we needed to find a way to combine the statistics of each individual player with the statistics of his/her team so that our model could output what team was expected to win instead of what player was expected to win. Therefore, we had to extend “champion select” from 1 attribute/column that listed the name of the champion to 136 new columns, one for each champion, that has a 1 if that champion was selected or 0 if not. After this we intuitively got rid of other attributes that we found trivial such as healing done, largest sprees, patch version, server/platform, and bans to reduce the dimensionality of our data to speed up training and testing. In the end, we were left with the following 144 features:
- 136 attributes for each champion/character in bag-of-words like state
- total wards placed by team
- first baron
- first turret
- first inhib
- team with first blood
- first rift herald
- first dragon
- side (blue vs red)
Our class output is “Win” that is 0 for defeat and 1 for victory.
Trial and Error
After we have chosen our attributes, we decided to play with our Decision Tree learner. After numerous attempts to get the code to do what we wanted, we figured out how to construct a tree but in text form. This obviously hinders the visualibiity of our algorithm’s output, and so we have worked to make a visual that can be seen in Key Findings and Results. When constructing our final output of accuracies, the final tree, and being able to make predictions, we would say the hardest part was making it so the data was usable. The data we have obtained was in csv format, which looks nice in excel but can be hard to work with in conjunction to SKlearn and numpy.
In order to get and determine our final results, there was many trial and errors in getting what we wanted as an output. SKlearn and Graphviz were very helpful in helping us get to our goal, but there were many limitations in documentation and our data constantly exceeding the memory limit of our computers. This is why we chose to use only a portion of the data that we have for this project, but it is very possible to have a more complete model made for this data set.
Key Findings and Results
As explained in “Choosing the Best Model”, Decision Trees was the learner we determined to be best fit. Once we chose CART/DT as our primary learner, we were able to determine of these which were the most impactful features on the outcome of the game by looking at what attributes cause the first few splits.
The diagram below shows the first 5 layers of our tree generated with 10000 samples. The most important attribute is whether or not a team has secured the first inhibitor. Afterwards, other team statistics such first baron and if a team placed a substantial amount of vision wards (>66) are important. Surprisingly, in the third and fourth layer, the specific champions selected begin to strongly influence whether or not a team is likely to win. Based on our tree below, teams with Orianna, Tryndamere, Rakan, or Ahri are more likely to win whereas teams with Varus, Caitlyn, Taliyah, Singed, and Ekko are more likely to lose.
If we look into deeper layers or at the entire generated decision tree, we can see that first tower and other champions also play a substantial role in the game outcome. For example, having a Yasuo on the team dropped the likelihood that the team would win. Additionally, we were surprised to find out that the side a team is on (denoted by teamid being 100 or 200) plays an insignificant role despite teams usually having a preference for one over the other. We were also surprised to find out that first blood (which team got the first champion kill) did not play a big role in determining what team would win. In the end, our model had achieved a 10-fold CV accuracy of 84.962% with 100,000 examples at 79.751% with 1000 examples. Unfortunately, creating the tree diagram for the 100,000 sample tree took too long so we are not able to show it.
These results indicate that teams should not feel discouraged if they are the first to die or if they get the side they do not prefer. It also indicates that teams should focus on objectives such as vision, inhibitors and barons since those are the attributes that greatly increase the likelihood a team wins. Our model would also encourage people to play supporting champions such as Orianna, Ahri, and Rakan while avoiding difficult to play champions such as Taliyah, Singed, and Ekko.
Team Objectives to Focus



Champions to Pick



Champions to Avoid



Reflection and Future Development
Ultimately, not only did we learn more about the game, but we also learned about data cleaning, attribute selection, new python packages, and new learners such as SVM during the course of this project. It was very interesting to see how analyzing the criteria of the data is important when choosing a good learner (similar to the first exercises on the midterm and final exam).
To divided the work that has been done in this project, we can say that we both have done equal amounts of work. Nicolas worked primarily on parsing through the dataset that can be used in a program as well as interpreting our resutls, while David created the python codes and visuals. The walls of division of the project were very transparent however, where David and Nico continued build on top of each other’s work.
For future development on this project, we would like to see if we could taylor the learner/predictor to specific players. Since different players have different playstyles (League of Legends is a very complicated game…), only picking out games from one player and analyzing what factors of the game lead them to win most of the time could provide useful insight to improving their gameplay, hitting high ranks, and ideally landing a spot in the Pro-Scene. Another future development would be able to predict which team will win a match even before the match has even started. This will be based on purely what each player’s skill level is, what champions they choose, and previous games played.